2.大數據(Big Data)的本質
機器智能離不開數據,那么大量的數據和現在大家所說的大數據是否是一回事呢?如果不是,它們之間又有什么聯系和區別呢?
毫無疑問,大數據的數據量自然是非常大的,但是光是“量”大還不是我們所說的大數據。比如過去國家統計局的數據量也很大,但是不是真正意義上的大數據。這兩者的差別我們可以從三個方面來看。
首先,大數據具有多維度性質,而不同維度之間有著天然的(而非人為的)聯系。為了說明這一點,我們不妨看一個實際的例子。
2013年9月份,百度發布了一個頗有意思的統計結果《中國十大“吃貨”省市排行榜》。百度沒有做任何的民意調查和各地飲食習慣的研究,它只是從“百度知道”的7700萬條和吃有關的問題里“挖掘”出來一些結論:
在關于“什么能吃嗎?”的問題中,福建、浙江、廣東、四川等地的網友最經常問的是“什么蟲能吃嗎”,江蘇、上海、北京等地的網友最經常問“什么的皮能不能吃”,內蒙古、新疆、西藏,網友則是最關心“蘑菇能吃嗎”,而寧夏網友最關心的竟然是“螃蟹能吃嗎”。寧夏的網頁關心的事情一定讓福建的網友大跌眼鏡,反過來也是一樣,他們會驚訝于有人居然要吃蟲子。
百度做的這件小事其實就是大數據的一個典型應用。它有這樣一些特點。首先,它的數據量非常“大”。第二,這些數據維度其實非常多,它們不僅涉及到食物的做法、吃法、成分、營養價值、價格、問題來源的地域和時間等等,而且里面包含了提問者的很多信息,互聯網的IP地址,所用的計算機(或者手機)的型號,瀏覽器的種類等等。這些維度也不是明確地給出的(這一點和傳統的數據庫不一樣),因此在外面人看來,這些原始的數據是“相當雜亂”,但是恰恰是這些看上去雜亂無章的數據將原來看似無關的維度(時間、地域、食品、做法,成分,人的身份和收入情況等)聯系了起來。經過對這些信息的挖掘,加工和整理,就得到了有意義的統計規律。
當然,百度只公布了一點點大家感興趣的結果。它完全可以從這些數據中得到更多有價值的統計結果。比如,它很容易得到不同年齡人、性別和文化背景(這些很容易挖掘出來)的飲食習慣,不同生活習慣的人(比如正常作息的、夜貓子們、經常出差的或者不愛運動的等等)的飲食習慣等等。如果百度的數據收集的時間跨度足夠長,它還可以看出不同地區人飲食習慣的變化,尤其是在不同經濟發展階段飲食習慣的改變。而這些看似很簡單的問題,比如飲食習慣的變化,沒有百度知道的大數據,還真難得到。這就是大數據多維度的威力。
大數據的第二個特點在于它的完備性。為了說明這一點,讓我們再來看一個真實的案例。從1932年開始,蓋洛普一直在對美國總統選舉進行預測,幾十年來它也在不斷地改進采樣的方法,力求使得統計準確,但是在過去的幾十年里,它對美國大選結果的預測可以講是大局(全國)尚準確,但是細節(每一個州)常常出錯。因為再好的采樣方法,也有考慮不周全之處。
但是到了2012年總統選舉時,這種“永遠預測不準”的情況得到了改變。一位名不見經傳的統計學家Nate Silver通過對互聯網網上能夠取得的各種大量的數據(包括社交網絡上用戶發表的信息、新聞信息和其它網絡信息),進行大數據分析,準確地預測了全部50個州的選舉結果,而在歷史上,蓋洛普從來沒有做的這一點。當然,有人可能會問,這個結果是否是蒙的?這個可能性或許存在,但是只有一千萬億分之一,因此可以認為這是大數據分析的結果。在這個例子中,Silver并沒有什么好的采樣方法,只是收集的數據很完備。大數據的完備性,不僅有用,甚至有點可怕。
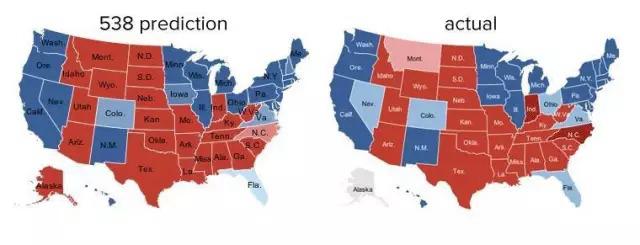
圖4. Nate Silver對2012年美國大選的預測(左)和實際結果(右)的對比(紅色的地方表示共和黨獲勝的州,藍色的表示民主黨獲勝的州)
數據的完備性的作用遠比準確預測一個總統選舉大得多,Google無人駕駛汽車便是一個很好的例子。首先,無人駕駛汽車可以算是一個機器人,這點應該沒有疑問,因為它能像人一樣對各種隨機突發性事件快速地做出判斷。在這個領域Google只花了六年時間就做到了全世界學術界幾十年沒有做到的事情。在2004年,經濟學家們還認為司機是計算機難以取代人的幾個行業之一。當然,他們不是憑空得出這個結論的,除了分析了技術上和心理上的難度外,還參考了當年DARPA組織的自動駕駛汽車拉力賽的結果--當時排名第一的汽車花了幾小時才開出8英里,然后就拋錨了。但是,僅僅過了6年后,2010年Google的自動駕駛汽車不僅研制出來了,而且已經在高速公路和繁華的市區行駛了14萬英里,沒有出一次事故。
為什么Google能在不到六年的時間里做到這一點呢?最根本的原因是它的思維方式和以往的科學家們都不同--它把這個機器人的問題變成了一個大數據的問題。首先,自動駕駛汽車項目是Google街景項目的延伸,Google自動駕駛汽車只能去它“掃過街”的地方,而在行駛到這些地方時,它對周圍的環境是非常了解的,這就是大數據完備性的威力。而過去那些研究所里研制的自動駕駛汽車,每到一處都要臨時地識別目標,這是人思維的方式。其次,Google的自動駕駛汽車上面裝了十幾個傳感器,每秒鐘幾十次的各種掃描,這不僅超過了人所謂的“眼觀六路、耳聽八方”,而且積攢下來的大量的數據,對各地的路況,以及不同交通狀況下車輛行駛的模式有準確的了解,計算機學習這些“經驗”的速度則遠遠比人快得多,這是大數據多維度的優勢。這兩點是過去學術界所不具備的條件,依靠它們,Google才能在非常短的時間里實現汽車的自動駕駛。
大數據的第三個特征在它的英文提法“Big Data”這個詞當中體現的很清楚。請注意,這里使用的是Big Data,而不是Large Data。Big和Large這兩個單詞有什么區別呢,Big更主要是強調抽象意義上的大,而Large是強調數量(或者尺寸)大,比如大桌子Large Table。Big Data的提法,不僅表示大的數據量,更重要地是強調思維方式的不同。這種以數據為主的新的做法,在某種程度上顛覆了我們長期以來在科學和工程上的方法論。在過去,我們強調做一件事情的因果關系,通過前提和假設,推導出結果。但是在大數據時代,由于數據的完備性,我們常常是先知道結論,再找原因(甚至不去找原因),那么我們是否愿意去接受這樣的工作方式。事實上,在一些具有大數據的IT公司里,包括Google,阿里巴巴等,今天已經是按照這種思維方式做事情了。Google的產品比競爭對手稍微好一點,主要不是靠技術,而是靠它的數據比對手更完備,同時它愿意用數據來解決問題。阿里巴巴的小額貸款能做起來(而其它商業銀行做不到),其實就是對大數據思維的一種詮釋。這是一種我們以前完全沒見過的新的思維方式,一種新的方法論。
大數據的這三個特點導致了機器智能和人具有完全不同的特點,它不是通過邏輯推理歸納演繹得出結論,而是利用大數據的完備性和多維度特點,直接找到答案。而大數據的完備性有可能讓機器比人更能夠掌控全局,或者說幫助決策者更好地掌握全局。
大數據不僅僅是數據量大,而在于它的天然多維度特點和它的完備性。數據驅動的方法結合呈指數增長的計算機性能導致了機器智能的產生,并且在今天這個時間點上可以比肩人類的智能,這才是大數據重要的根本原因。機器智能和人的智能是不同的,它不是依靠人嚴密的邏輯推理得到問題的答案,而是通過大數據的完備性直接找到答案,或者根據大數據多維度的特點找到以前我們無法發現的規律性。這將改變我們的思維方式,也就是所謂的采用“大數據思維”。
轉載請注明:北緯40° » 大數據、機器智能和未來社會的圖景



